library(ggplot2)Tipos de gráficos
Las gráficas que se usen va a depender de los tipos de variables (numéricas o categóricas) que deseemos representar. Las más usadas son:
- Datos numéricos
- Histogramas
- Lineas
- Dispersión
- Datos categóricos
- Barras
- Pie
- Datos mixtos
- Boxplot
- Violin
Importación de librerias
Importar dataset
df <- read.csv(file = 'data/df_random.csv', sep = ',')
head(df, 3) col1 col2 col3 col4 col5 col6
1 19.9 19.6 18.2 1976 Tipo 3 Clase C
2 20.2 20.3 18.6 1977 Tipo 1 Clase A
3 20.2 19.4 18.4 1978 Tipo 2 Clase D1. Datos numéricos
a. Histogramas
El histograma nos muestra la distribucion de los datos de una variable numérica agrupados en rangos equidistantes.
Por ejemplo, para el atributo col1:
head(df[1], n=3) col1
1 19.9
2 20.2
3 20.2ggplot() +
geom_histogram(data = df,
aes(x = col1),
binwidth = 1,
color = "black")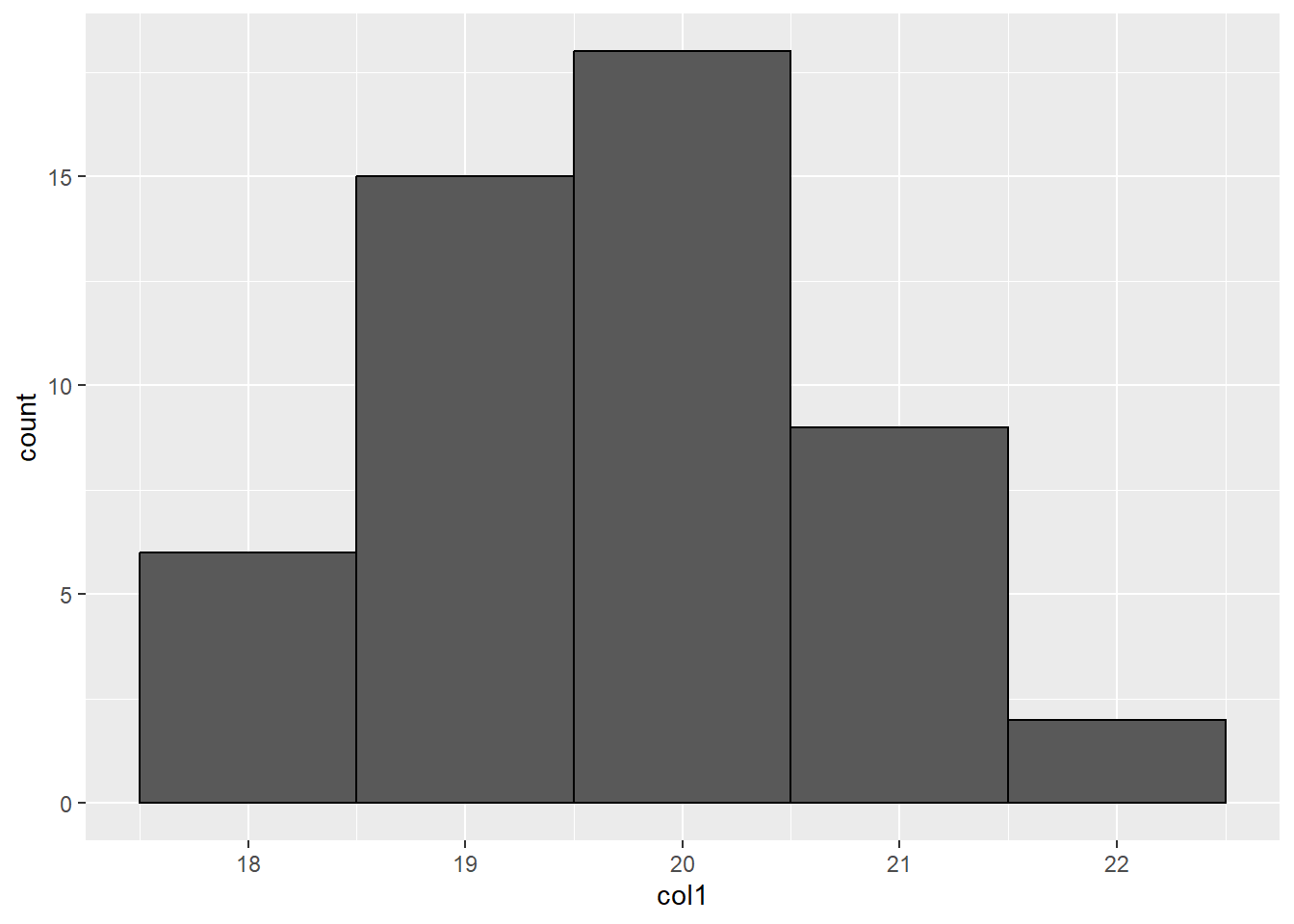
La orientación de la barras se cambia a horizontal agregando la capa coord_flip()
ggplot() +
geom_histogram(data = df,
aes(x = col1),
binwidth = 1,
color = "black") +
coord_flip()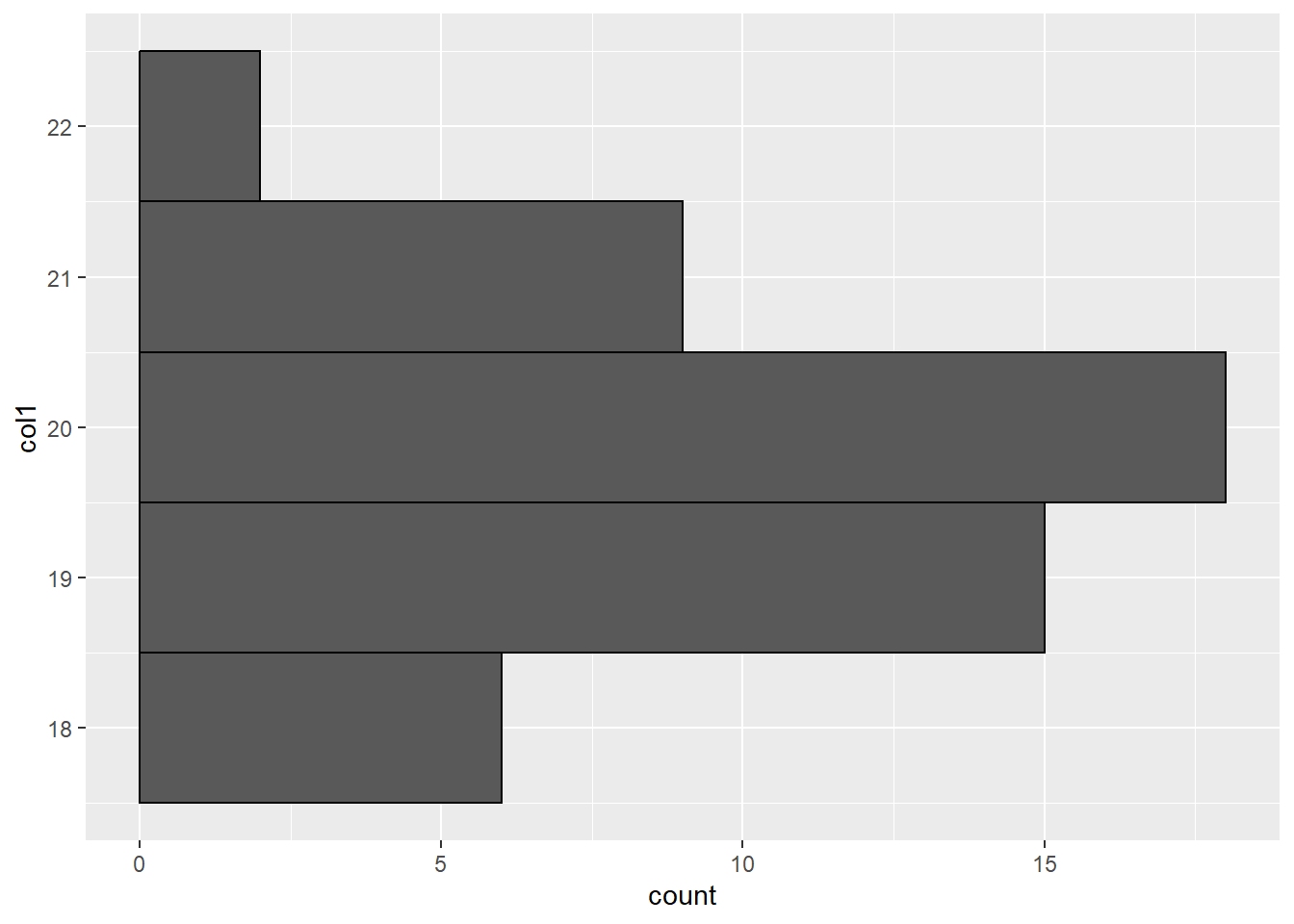
b. Lineas
El gráfico de Linea nos ayuda a ver la variación de un dato a lo largo del tiempo.
Por ejemplo, para los atributo col1 y col4:
head(df[c(1,4)], n=3) col1 col4
1 19.9 1976
2 20.2 1977
3 20.2 1978ggplot() +
geom_line(data = df,
aes(x = col4, y = col1))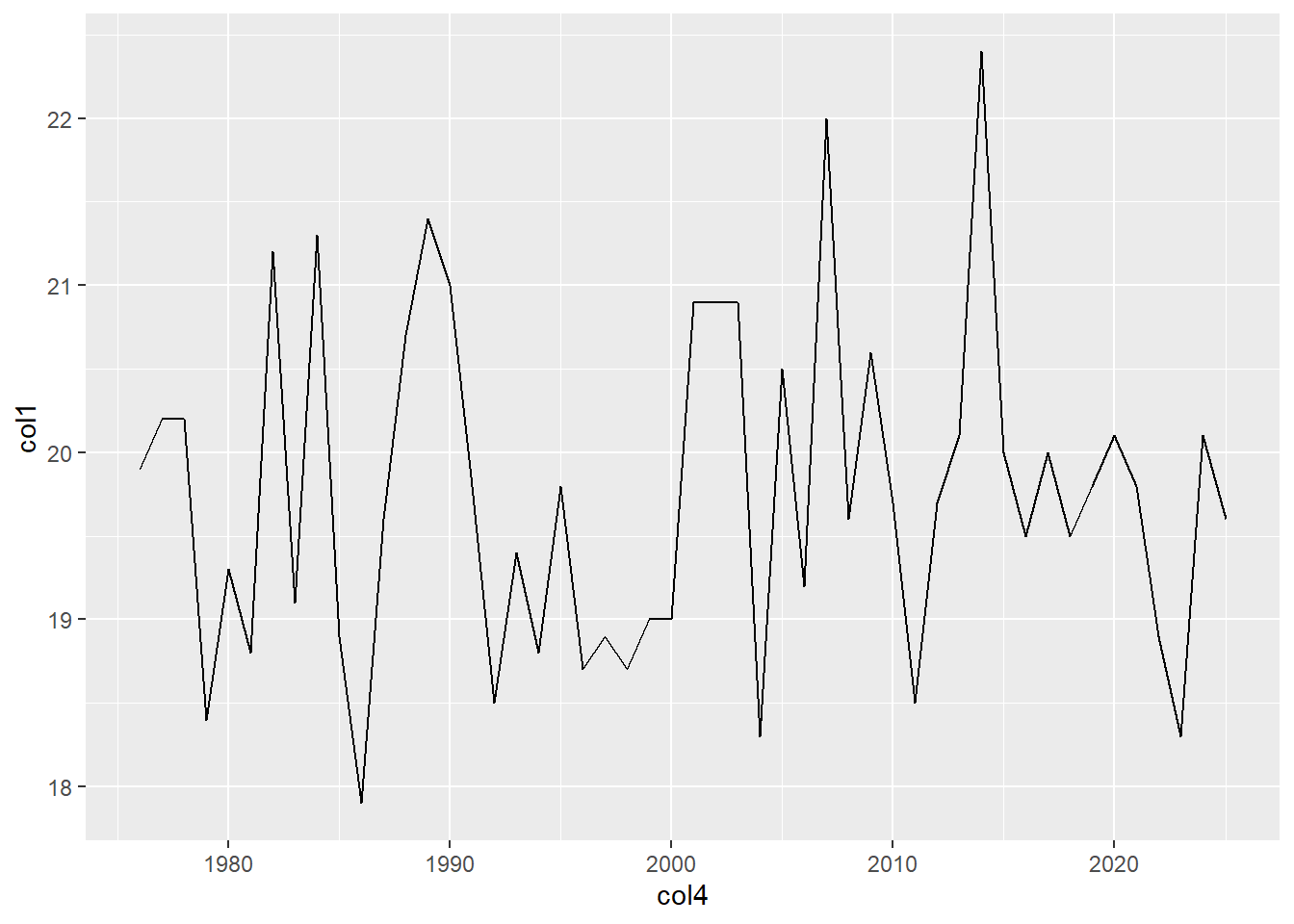
Personalizando el tipo de linea
ggplot() +
geom_line(data = df,
aes(x = col4, y = col1),
color = "blue",
lwd = 0.8,
arrow=arrow())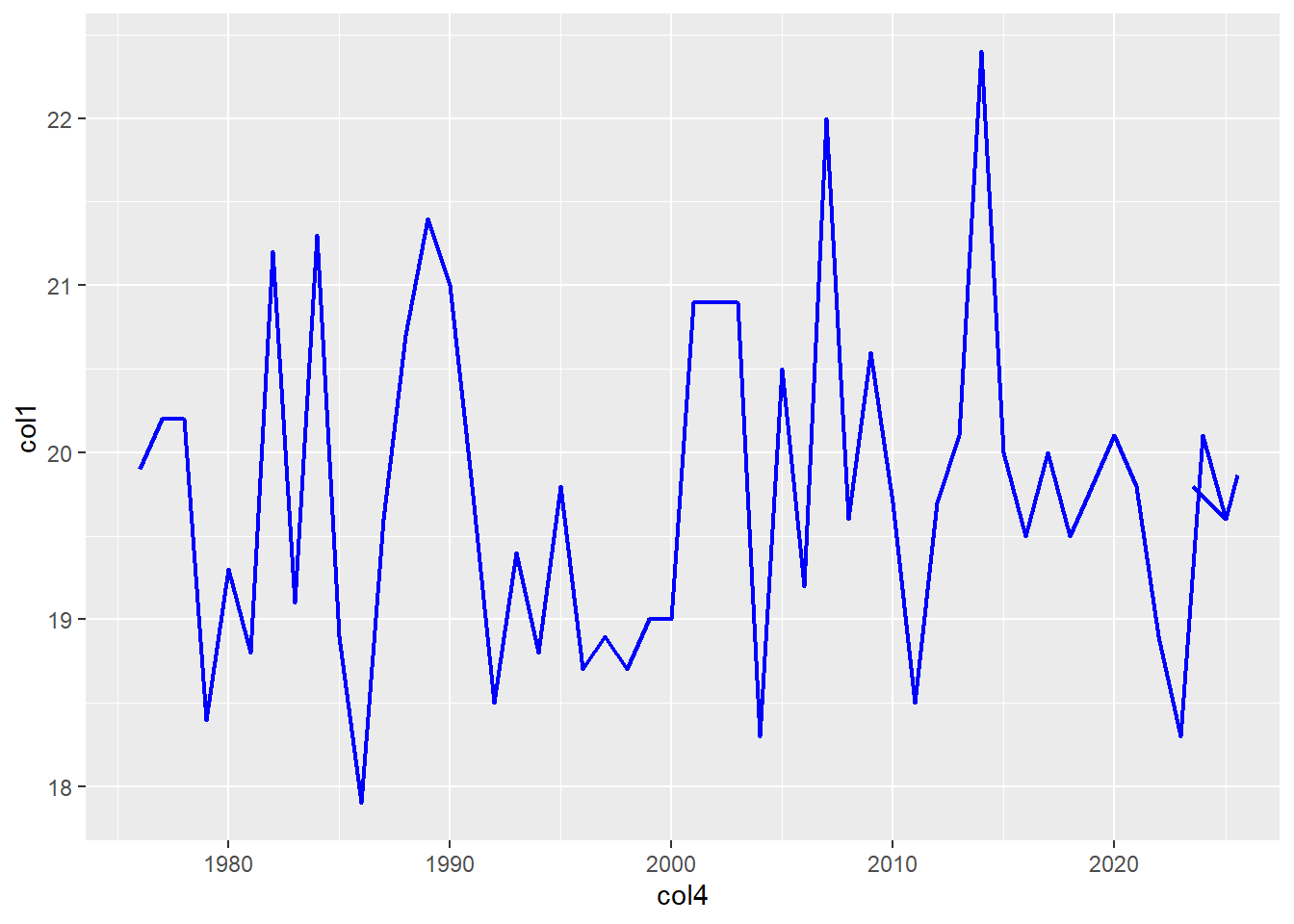
Podemos agregar más variables continuas (col1, col2, col3) para compararlas entre si:
head(df[c(1,2,3,4)], n=3) col1 col2 col3 col4
1 19.9 19.6 18.2 1976
2 20.2 20.3 18.6 1977
3 20.2 19.4 18.4 1978ggplot() +
geom_line(data = df,
aes(x = col4, y = col1),
color = "blue") +
geom_line(data = df,
aes(x = col4, y = col2),
color = "green") +
geom_line(data = df,
aes(x = col4, y = col3),
color = "red")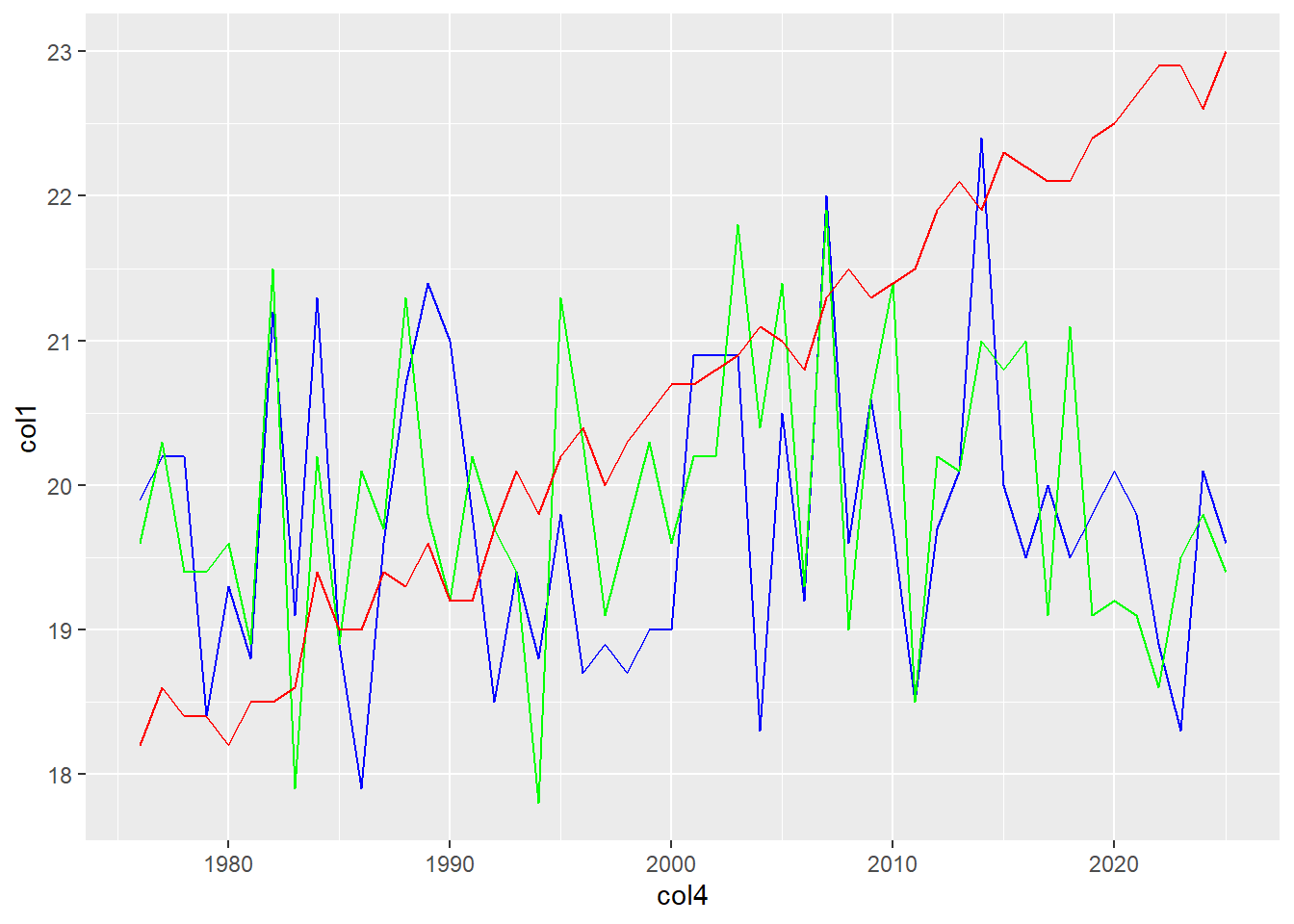
c. Dispersión
Las gráficas de dispersión permiten comparar dos variables numéricas para visualizar algun tipo de correlación entre ellas.
head(df[c(1,2)], n=3) col1 col2
1 19.9 19.6
2 20.2 20.3
3 20.2 19.4ggplot() +
geom_point(data = df,
aes(x = col1, y = col2))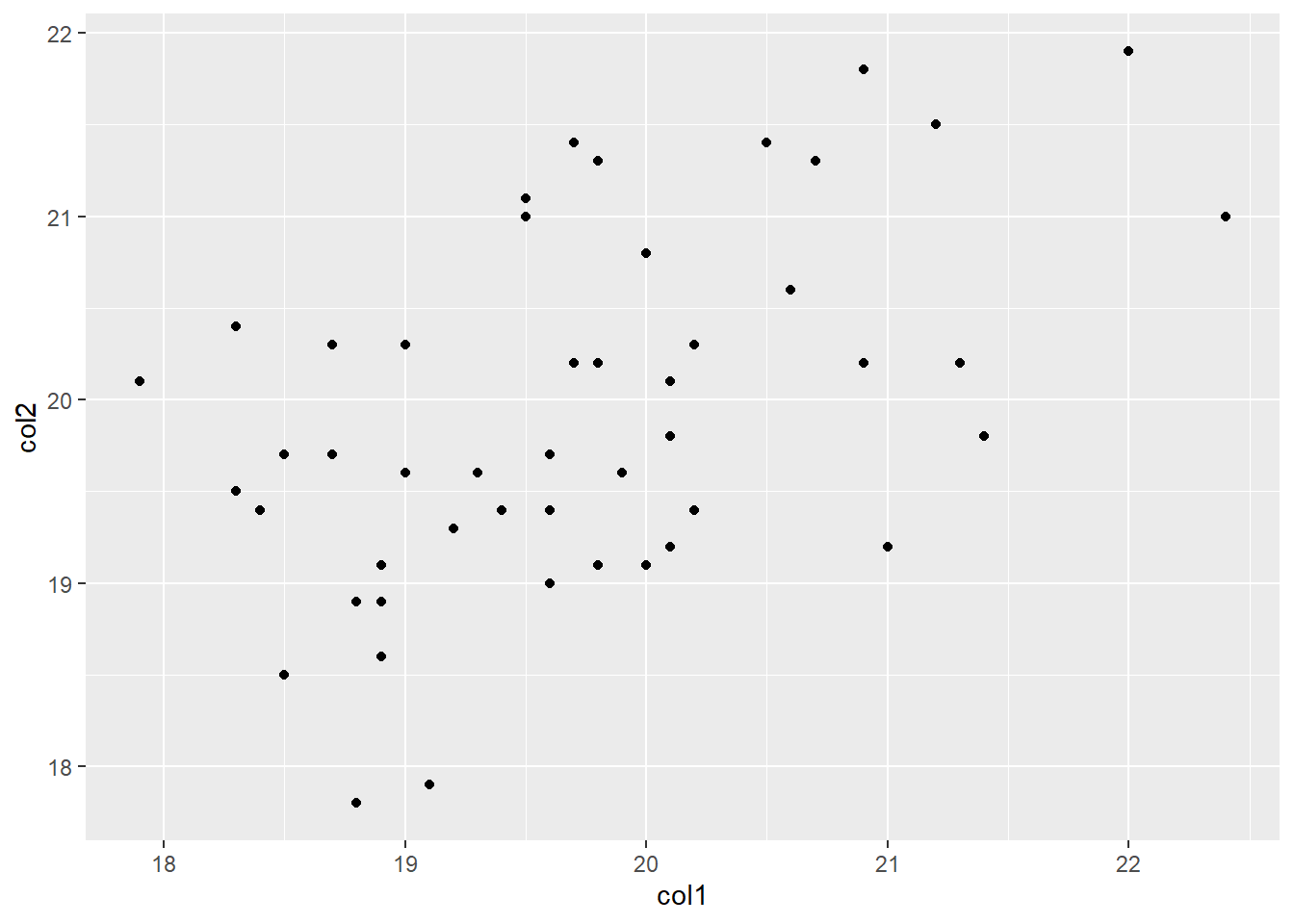
Agregando una linea para observar la tendencia entre las variables.
ggplot(data = df, aes(x = col1, y = col2)) +
geom_point() +
geom_smooth(method = "lm", color ="red",formula = y ~ x)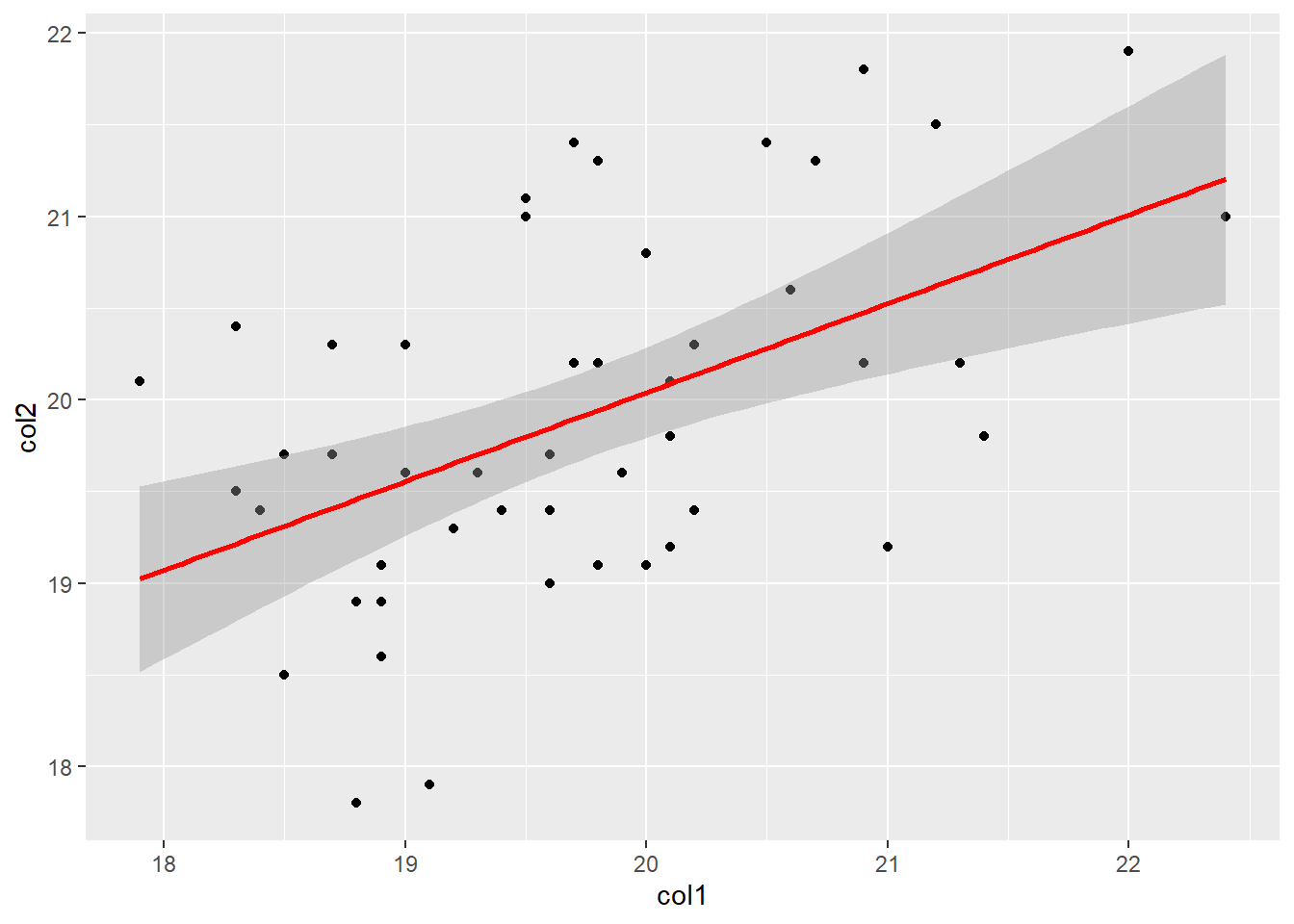
2. Datos categóricos
a. Barras
La gráfica de barras nos muestra la frecuencia con que se presentan los elementos de una variable categórica.
Para una variable categórica:
head(df[6], n=3) col6
1 Clase C
2 Clase A
3 Clase Dggplot() +
geom_bar(data = df,
aes(x = col6, fill = col6))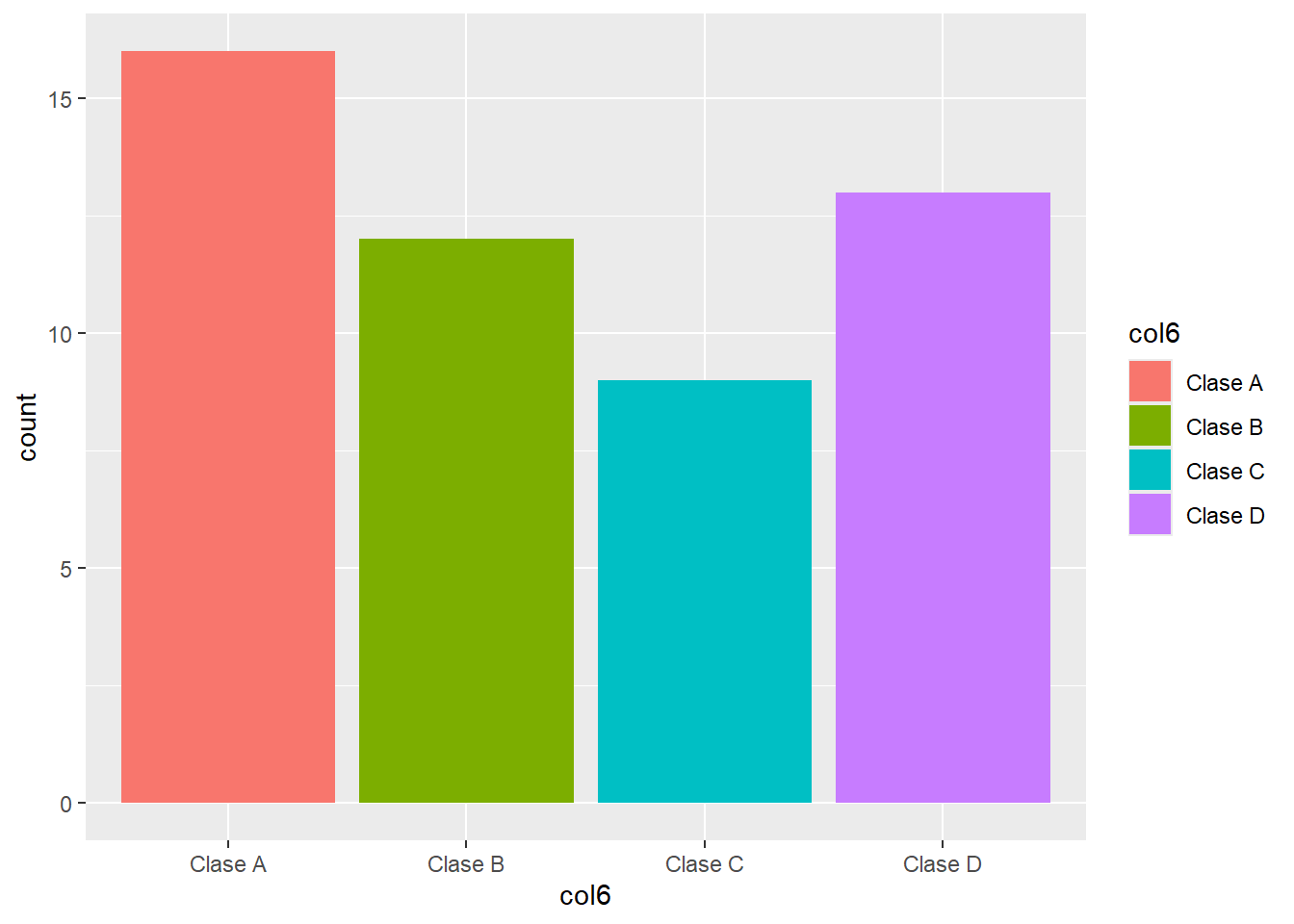
Para dos variables categóricas:
head(df[c(5,6)], n=3) col5 col6
1 Tipo 3 Clase C
2 Tipo 1 Clase A
3 Tipo 2 Clase Dggplot() +
geom_bar(data = df,
aes(x = col6, fill = col5))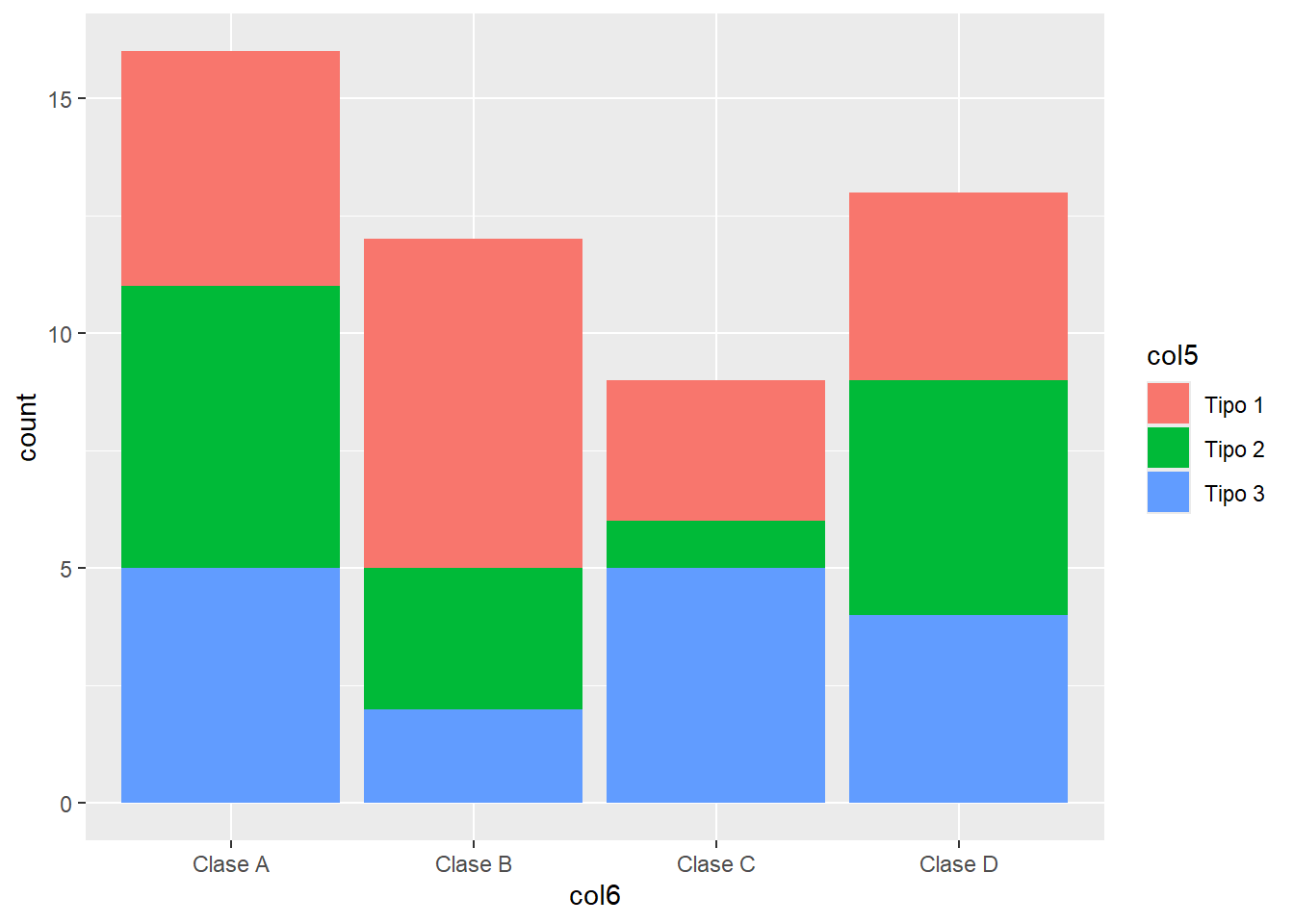
Podemos separar ambas categorías para que se muestren en columnas independientes.
ggplot() +
geom_bar(data = df,
aes(x = col6, fill = col5),
position = "dodge")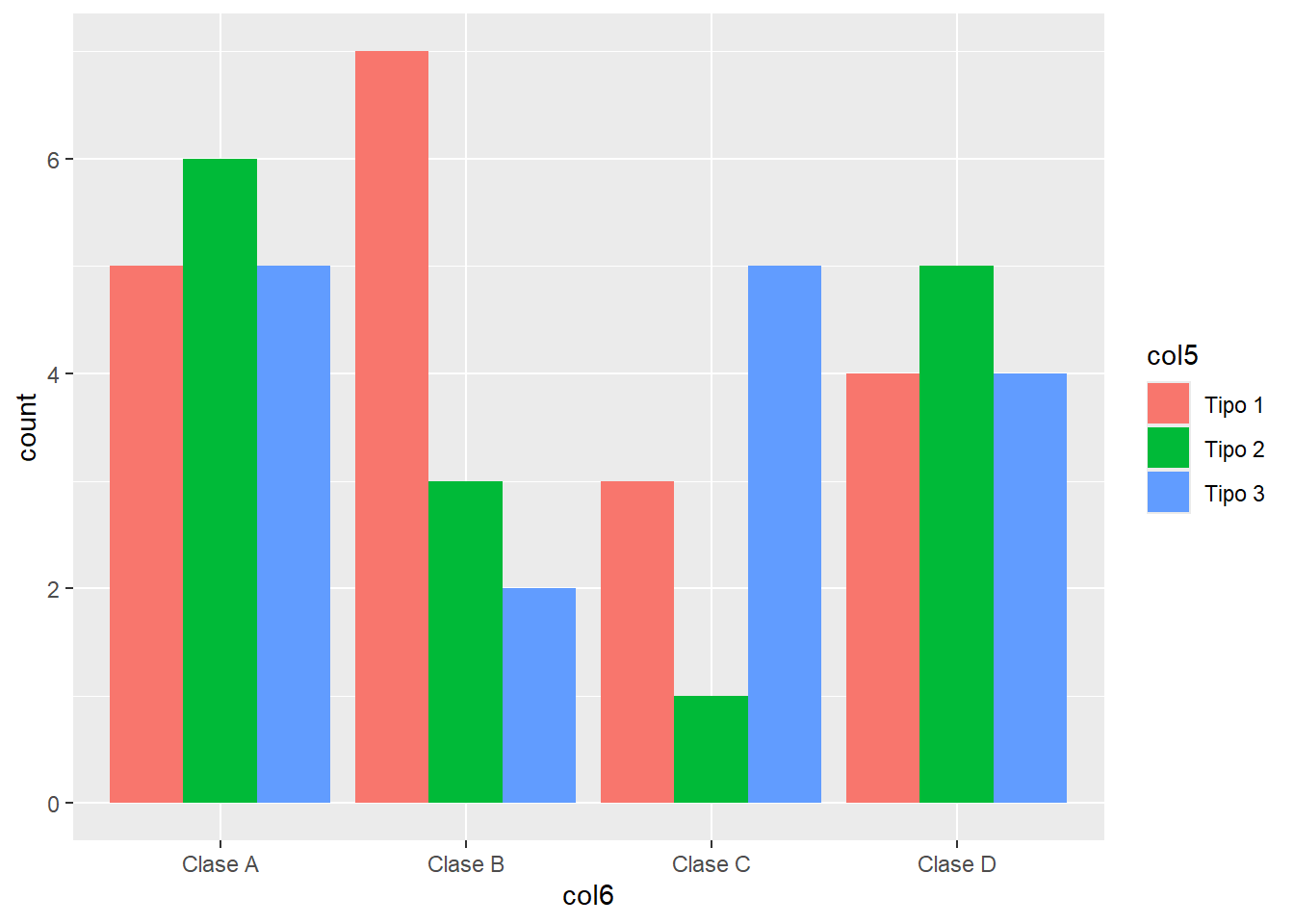
Si se quiere mostrar el valor de la cuenta en cada colunma, se tiene que modificar el dataframe.
# Extraer variables categoricas
df2 <- df[6]
# Conteo de elementos
df2 <- as.data.frame(table(df2))
df2 col6 Freq
1 Clase A 16
2 Clase B 12
3 Clase C 9
4 Clase D 13ggplot(data = df2, aes(x = col6, y = Freq, fill = col6)) +
geom_bar(stat="identity") +
geom_text(aes(x = col6, y = Freq, label = Freq),
position = position_stack(vjust = 0.5),
size = 4)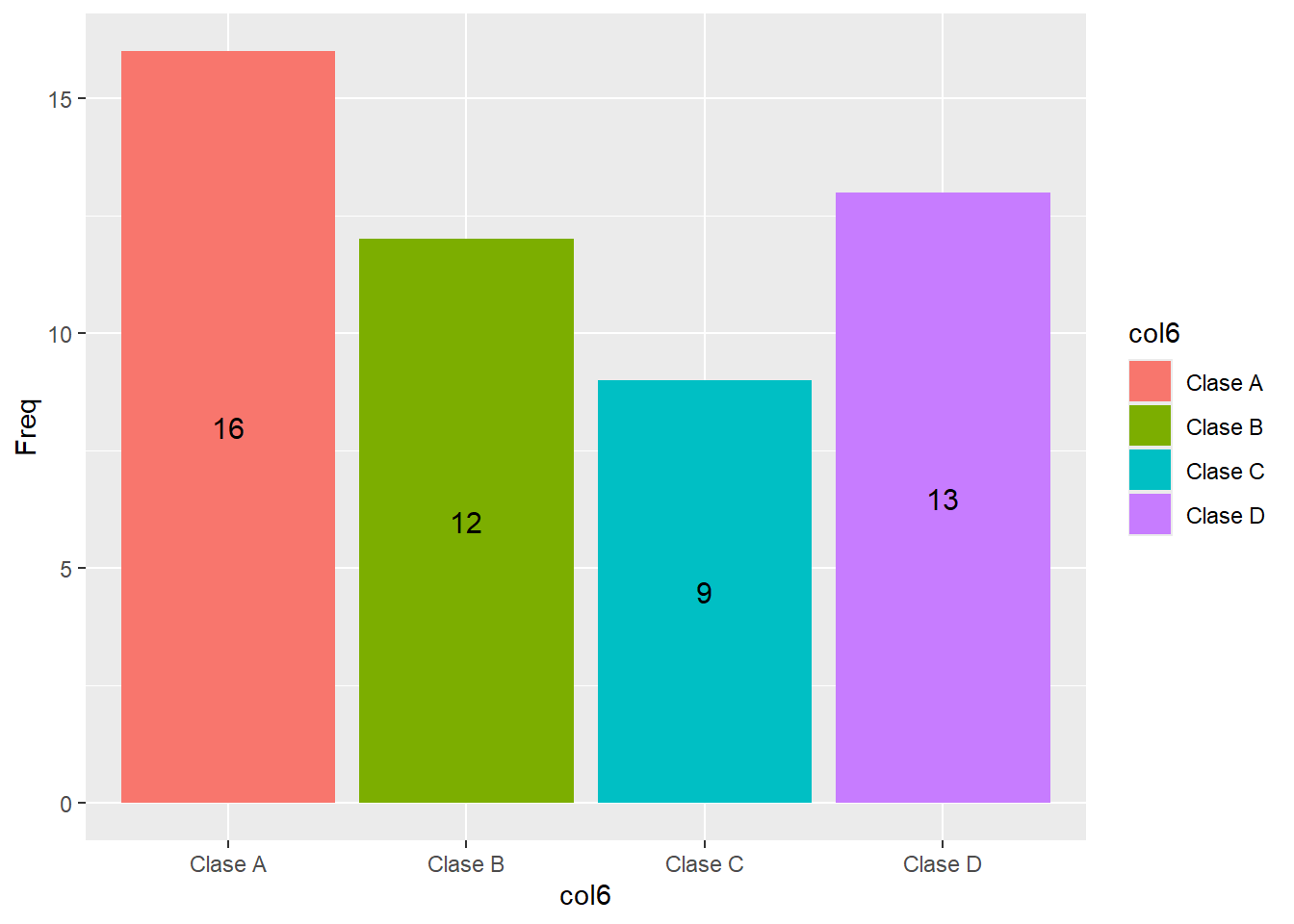
Lo mismo para dos variables categoricas.
# Extraer variables categoricas
df2 <- df[c(6,5)]
# Conteo de elementos
df2 <- as.data.frame(table(df2))
head(df2, n=3) col6 col5 Freq
1 Clase A Tipo 1 5
2 Clase B Tipo 1 7
3 Clase C Tipo 1 3ggplot(data = df2, aes(fill = col5, x = col6, y = Freq)) +
geom_bar(stat="identity") +
geom_text(aes(x = col6, y = Freq, label = Freq),
position = position_stack(vjust = 0.5),
size = 4)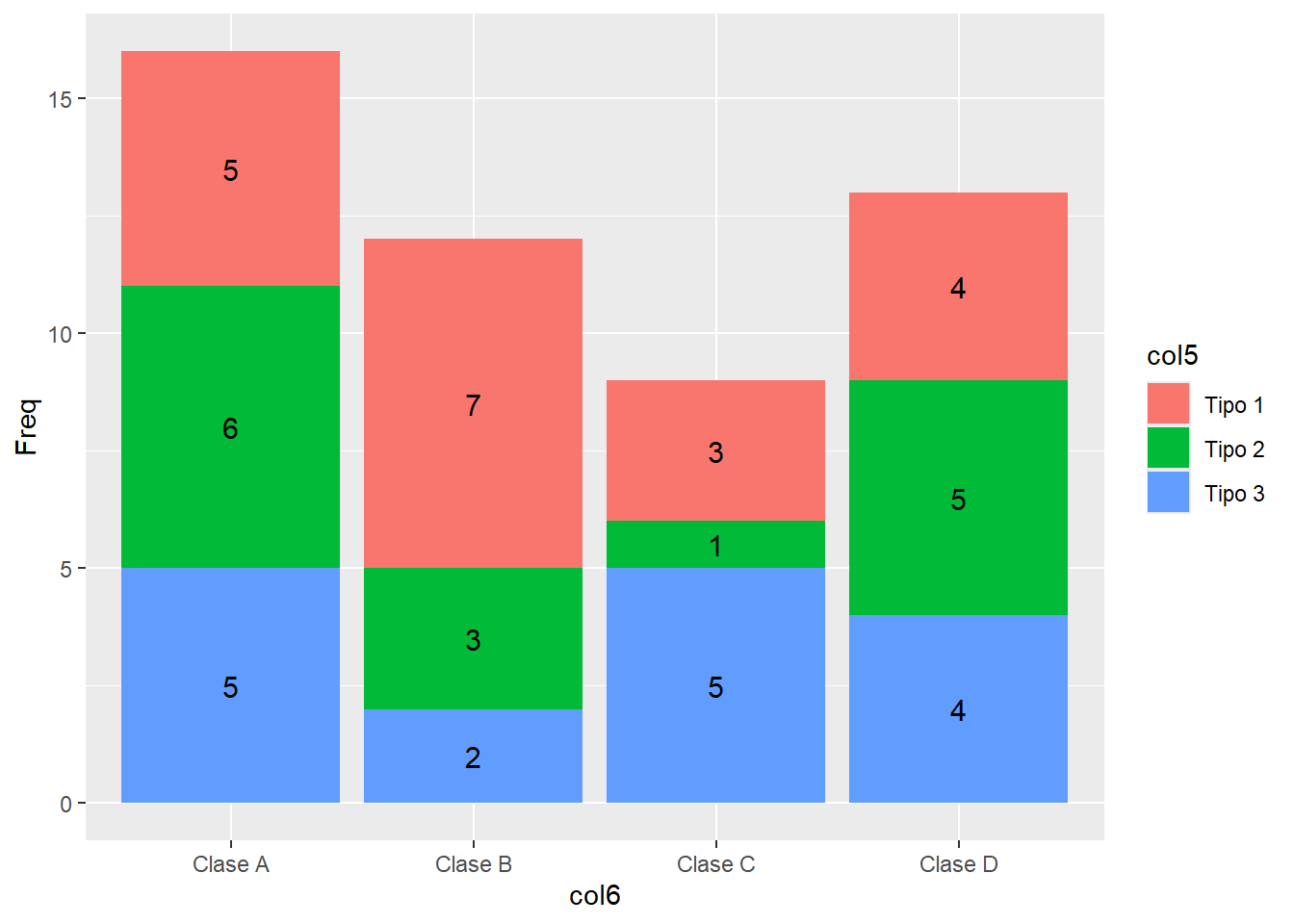
b. Pie
Un diagrama tipo Pie es una forma alternativa del diagrama de barras para una variable categórica.
# Extraer la variable categorica
df2 <- df[6]
# Conteo de elementos
df2 <- as.data.frame(table(df2))
df2 col6 Freq
1 Clase A 16
2 Clase B 12
3 Clase C 9
4 Clase D 13ggplot(df2, aes(x = Freq, y = "", fill = col6)) +
geom_col(color = "black") +
coord_polar(theta = "x") +
geom_text(aes(label = Freq),
position = position_stack(vjust = 0.5)) +
theme_void()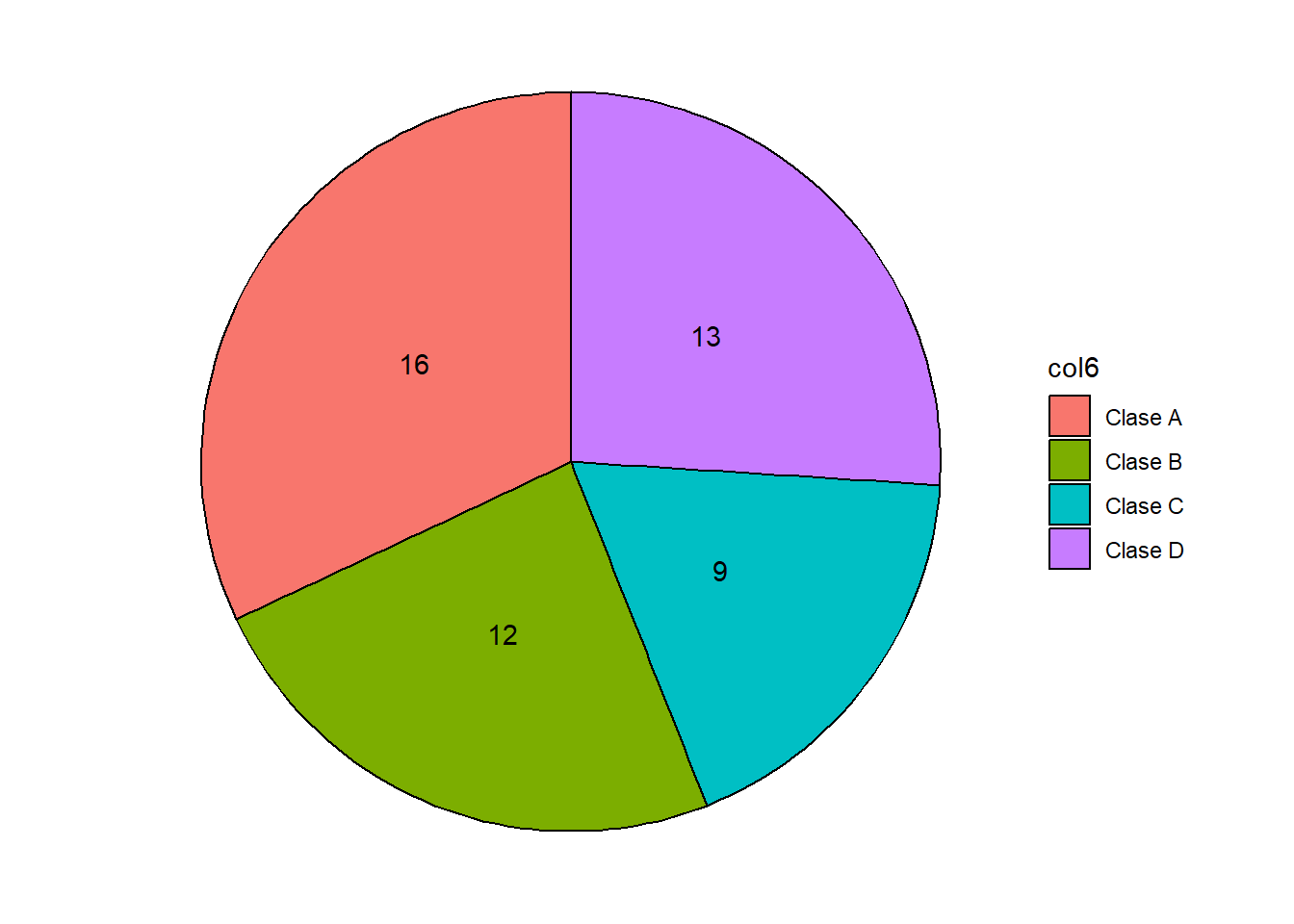
3. Datos mixtos
a. Boxplot
El diagrama de caja o Boxplot muestra como estan distribuidos los datos numéricos a traves de la interpretacion de 5 parámetros estadísticos:
- Valor mínimo
- Primer quartil
- Mediana
- Tercer quartil
- Valor máximo
Por ejemplo, para el atributo col1
head(df[1], n=3) col1
1 19.9
2 20.2
3 20.2Sus estadisticas seran:
summary(df$col1) Min. 1st Qu. Median Mean 3rd Qu. Max.
17.90 18.93 19.70 19.75 20.20 22.40 - Valor mínimo: 17.9
- Primer quartil: 18.93
- Mediana: 19.70
- Tercer quartil: 20.20
- Valor máximo: 22.40
ggplot() +
geom_boxplot(data = df, aes(y = col1))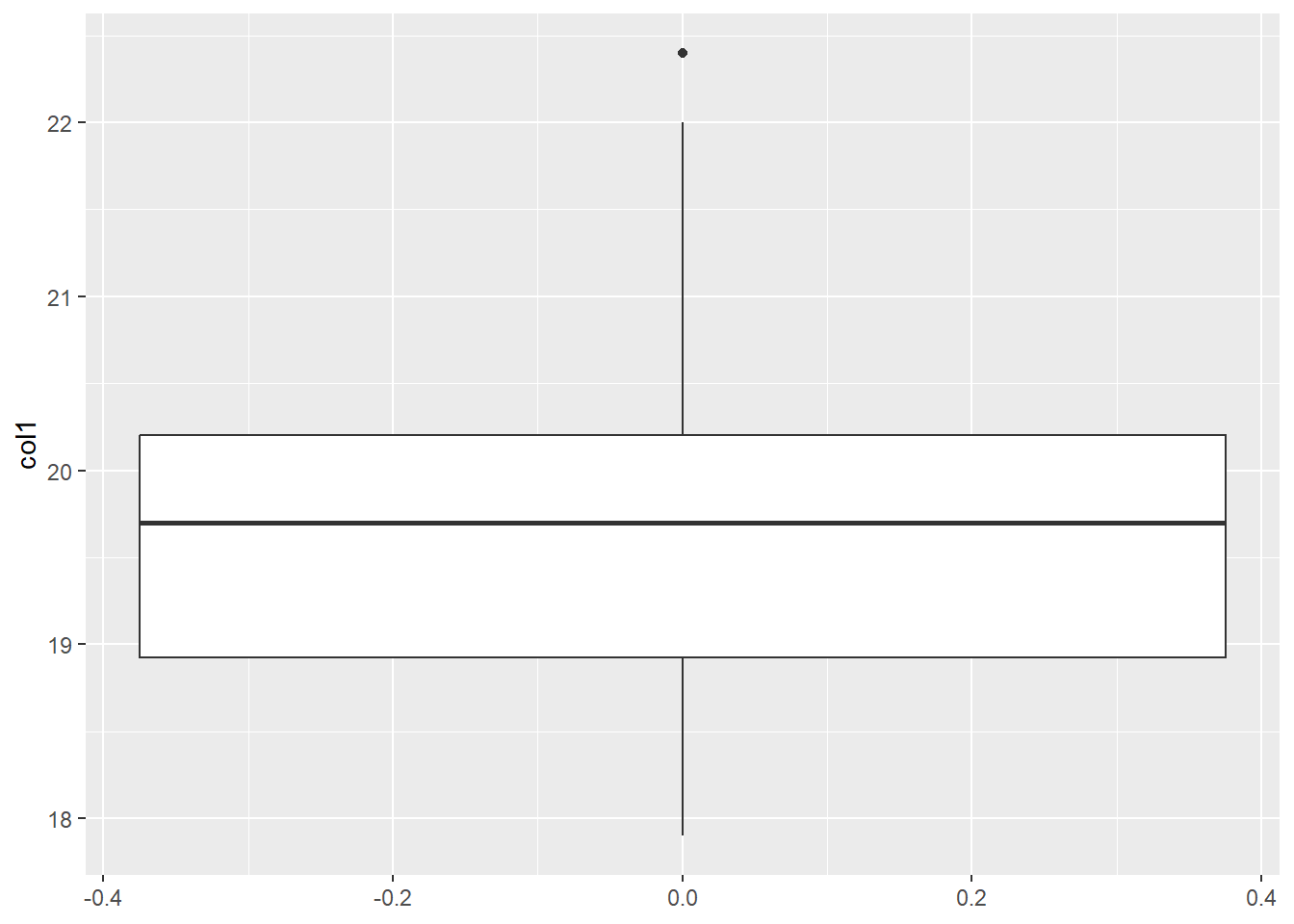
La gráfica anterior se interpreta del siguiente modo:
lbl <- data.frame(stat_x = c(0.2, 0.2, 0.2, 0.2, 0.2),
stat_y = c(17.9, 18.93, 19.70, 20.20, 22.40),
stat_lbl = c("Mínimo = 17.9", "1er quartil = 18.93",
"Mediana = 19.7", "3er Quartil = 20.20",
"Máximo = 22.40"))
ggplot() +
geom_boxplot(data = df, aes(y = col1)) +
geom_jitter(data = df,
aes(x = 0, y = col1),
color = 'green') +
geom_label(data = lbl,
aes(x = stat_x, y = stat_y, label = stat_lbl),
size = 4,
color = "blue",
fontface = "bold",
fill = "white")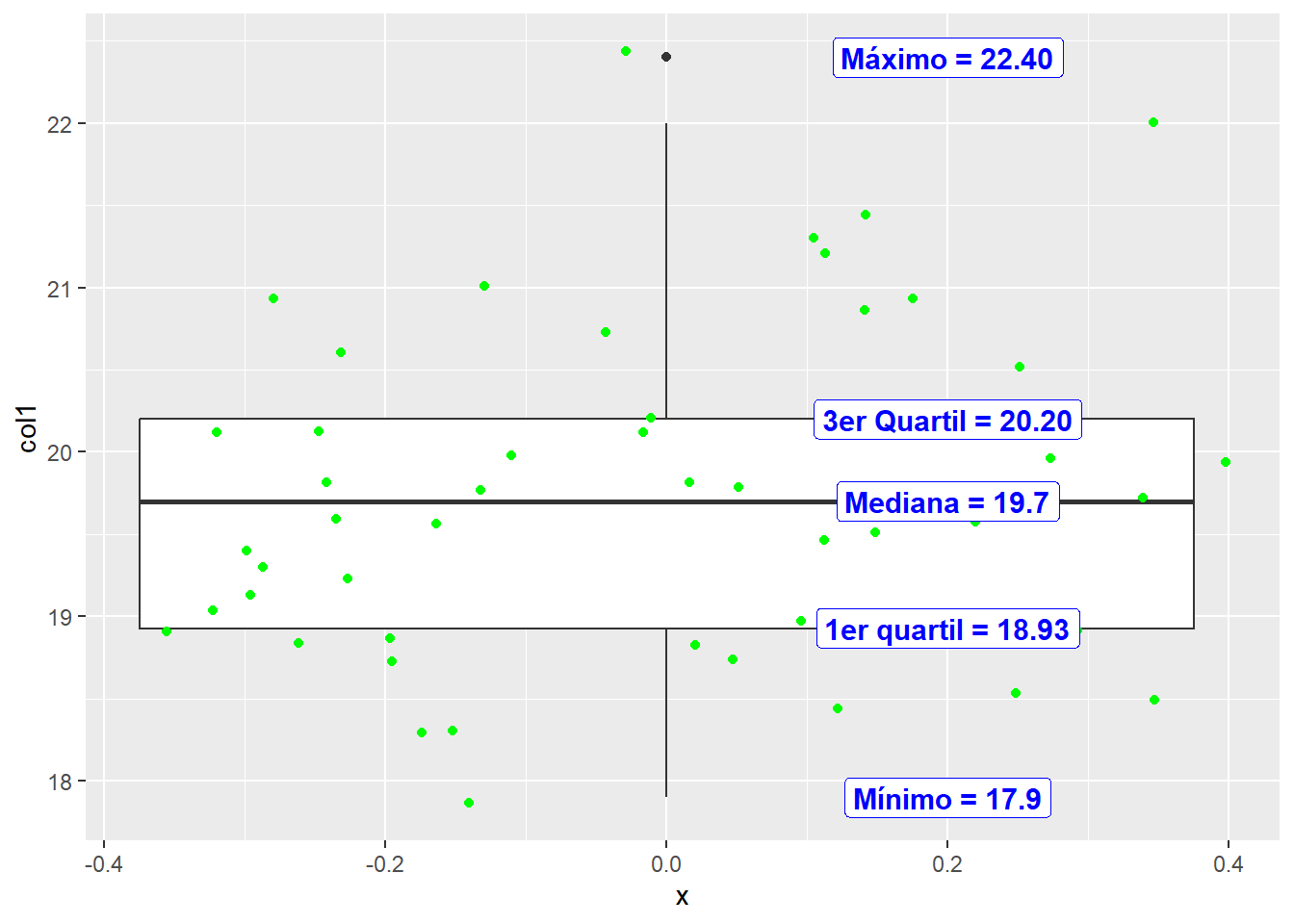
El Boxplot para cada clase será:
head(df[c(1,6)], n=3) col1 col6
1 19.9 Clase C
2 20.2 Clase A
3 20.2 Clase Dggplot() +
geom_boxplot(data = df,
aes(x = col6, y = col1, fill = col6))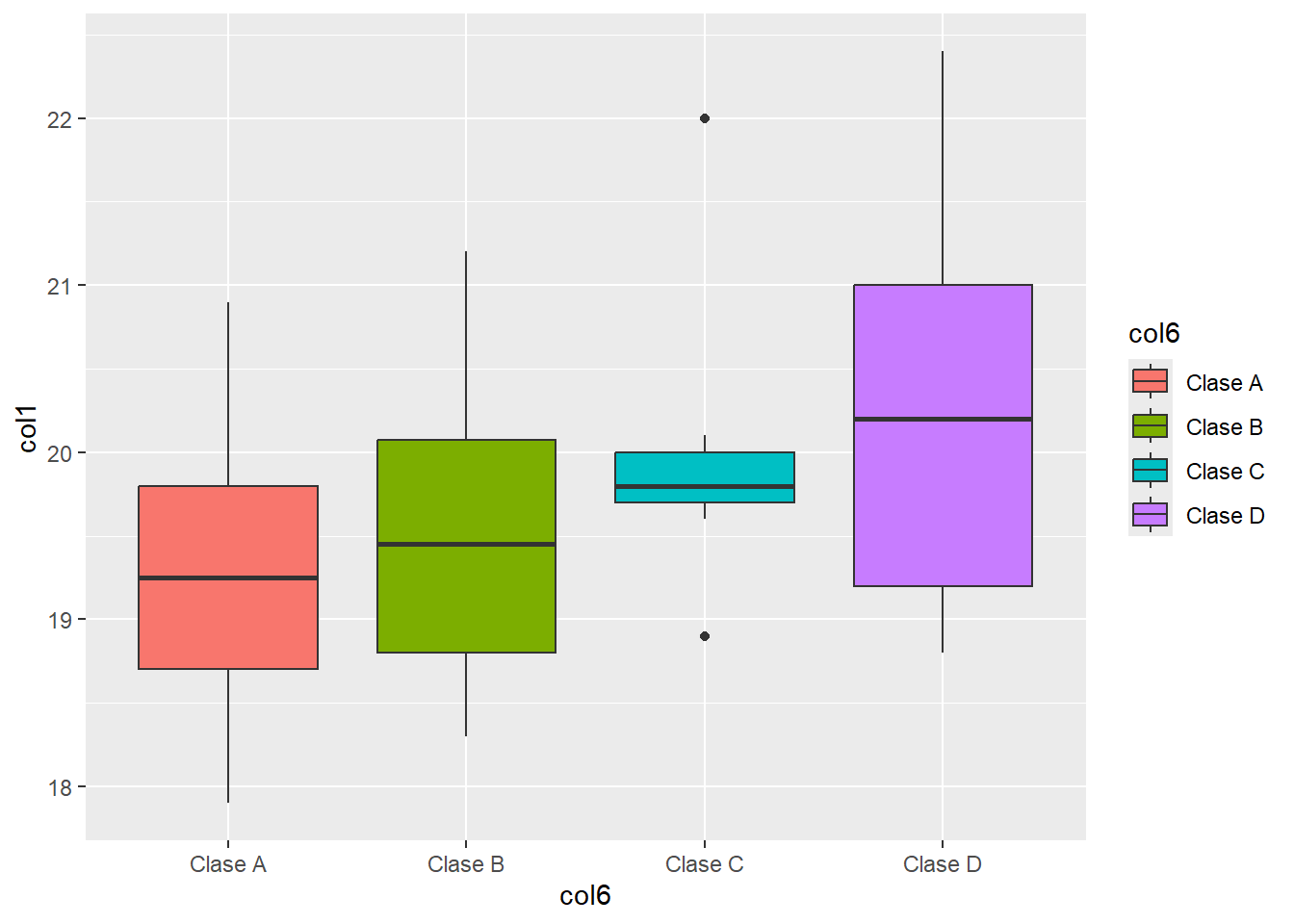
ggplot() +
geom_boxplot(data = df,
aes(x = col6, y = col1, fill = col6)) +
geom_jitter(data = df,
aes(x = col6, y = col1),
width = 0.2,
color = 'blue')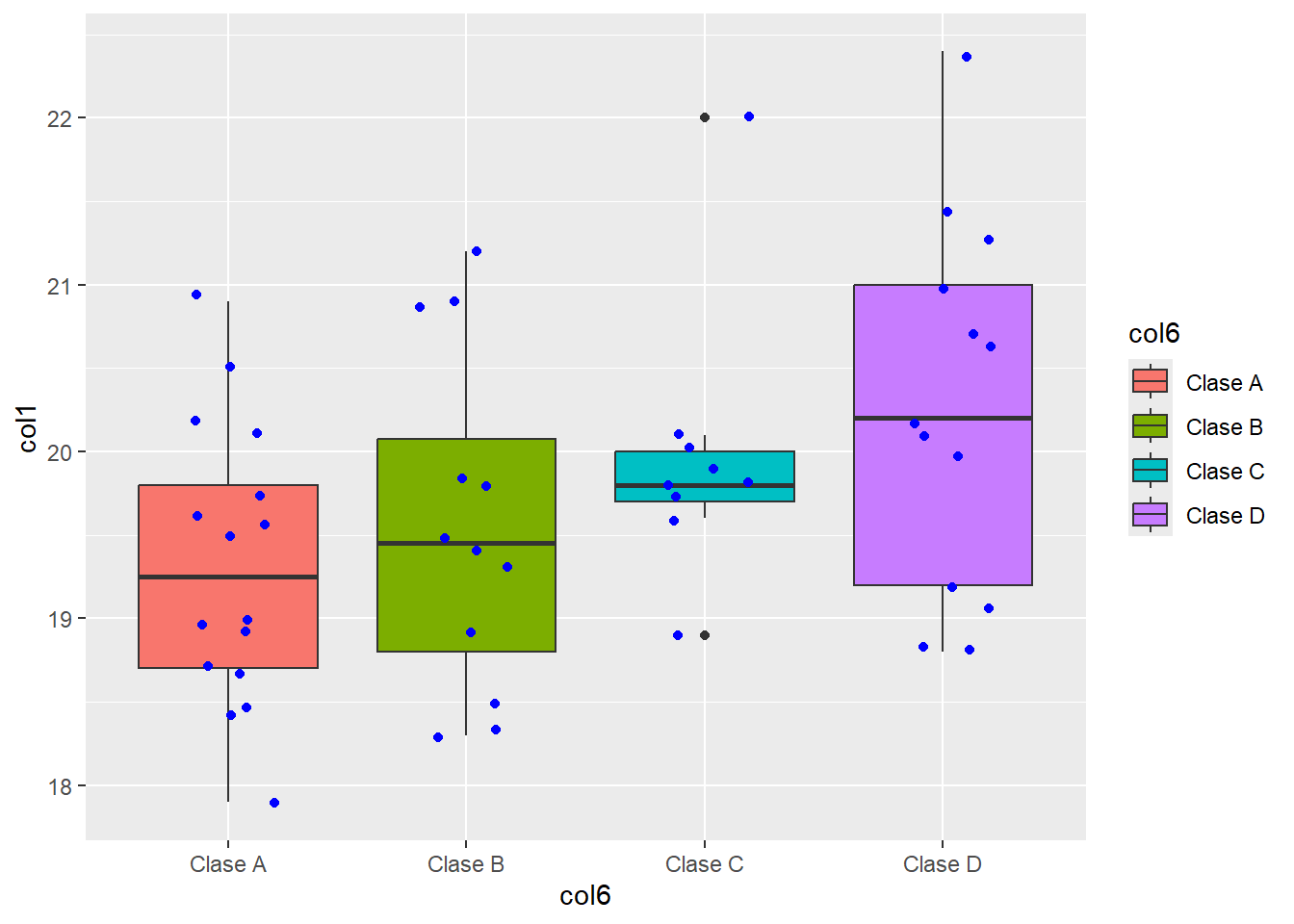
b. Violin
En el gráfico tipo Violin (similar al Boxplot) se representan parámetros estadísticos en función de la variación del ancho de sus bordes.
head(df[c(6,1)], n=3) col6 col1
1 Clase C 19.9
2 Clase A 20.2
3 Clase D 20.2ggplot() +
geom_violin(data = df,
aes(x = col6, y = col1, fill = col6))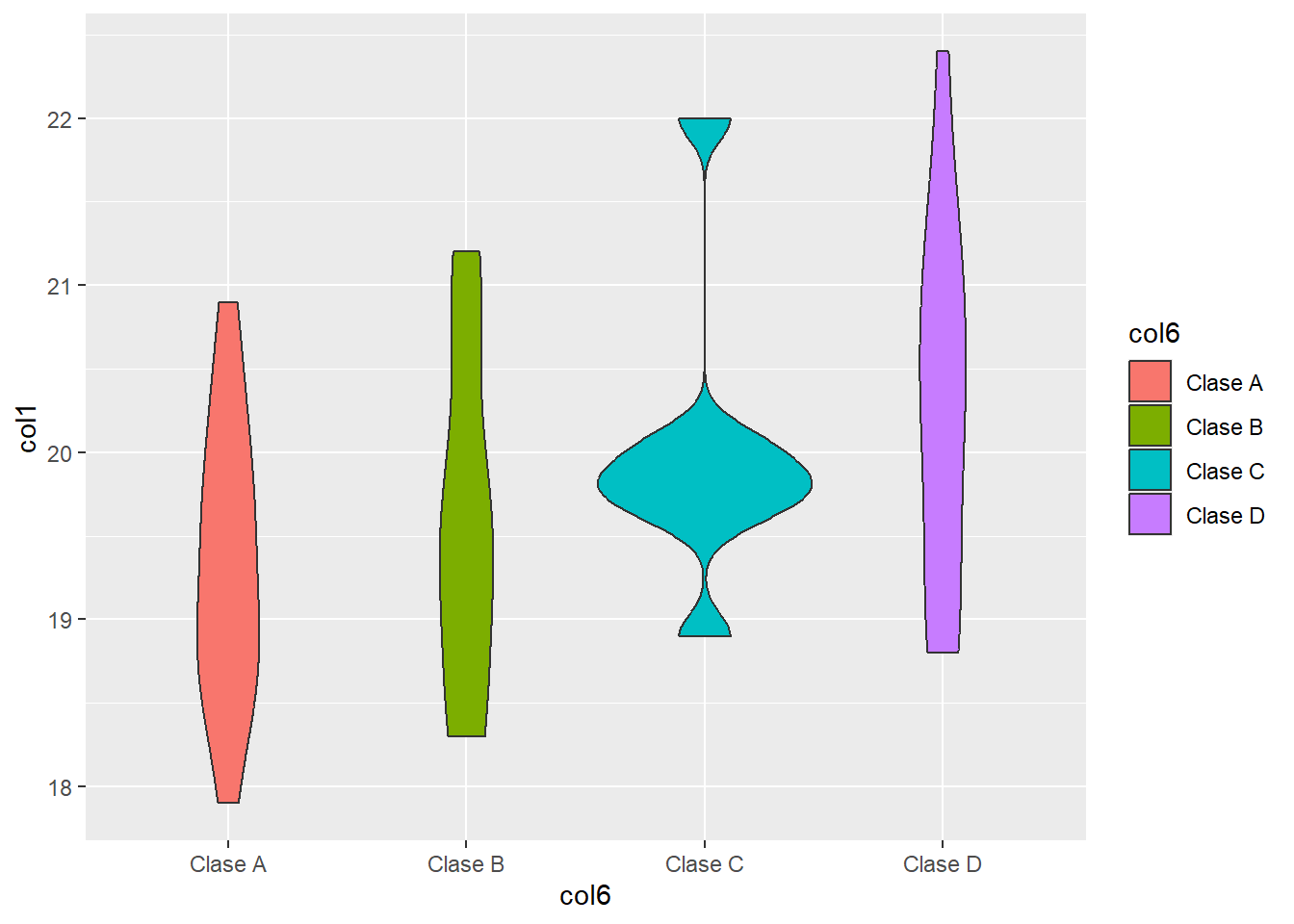
ggplot() +
geom_violin(data = df,
aes(x = col6, y = col1, fill = col6)) +
geom_jitter(data = df,
aes(x = col6, y = col1),
width = 0.2,
color = 'blue')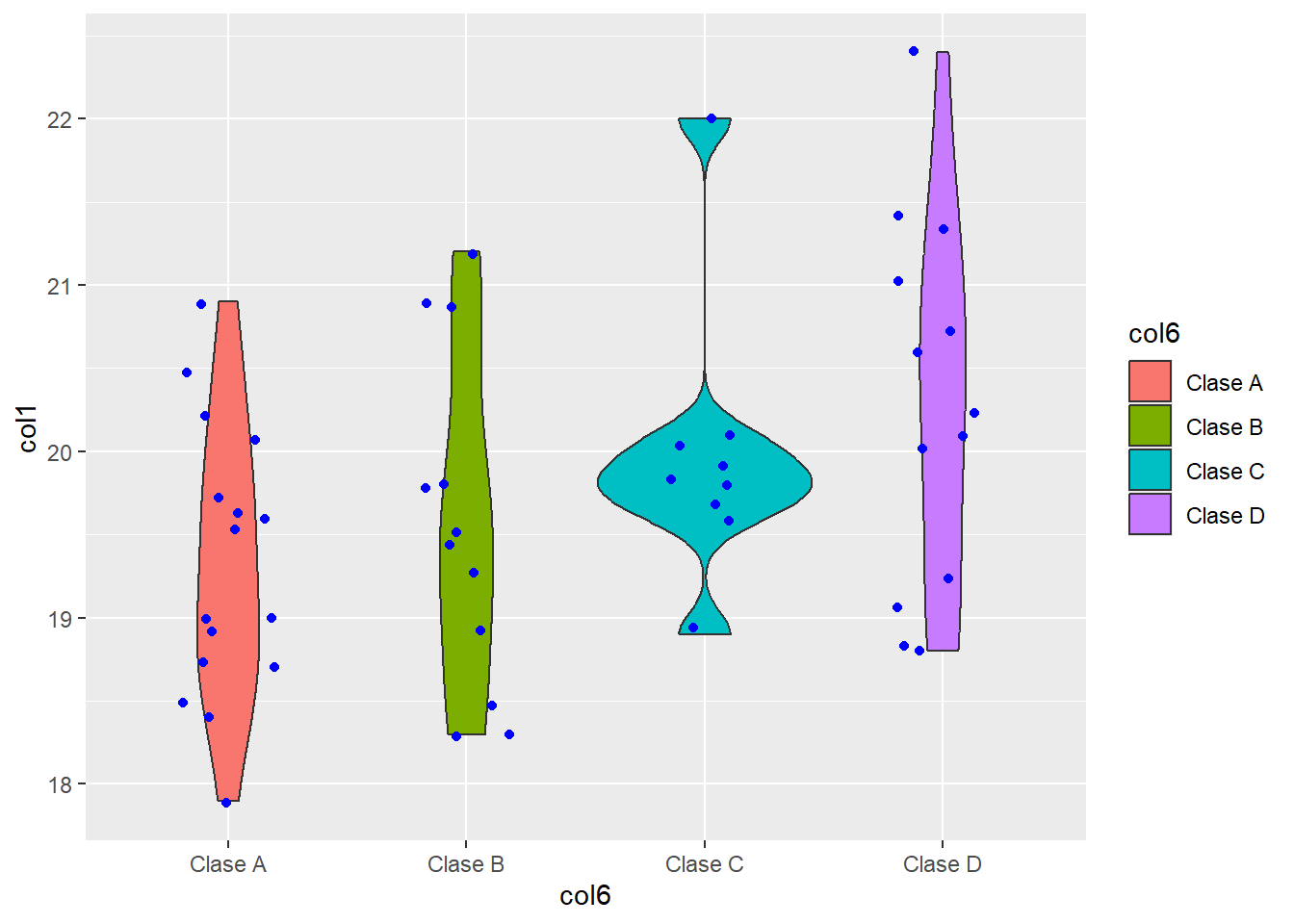
c. Barras
La gráfica de barras tambien puede emplearse para conocer la distribucion de los elementos de una variable numérica respecto a una categórica.
Por ejemplo, la variable numérica col1 esta presente en las diferentes clases de col6
head(df[c(6, 1)], n=3) col6 col1
1 Clase C 19.9
2 Clase A 20.2
3 Clase D 20.2Antes de generar el gráfico se realiza un conteo de col1 por cada clase del col6
df2 <- df[c(6, 1)]
df2 <- aggregate(col1 ~ col6, df2, sum)
df2 col6 col1
1 Clase A 309.2
2 Clase B 234.8
3 Clase C 179.8
4 Clase D 263.6ggplot(data = df2, aes(x = col6, y = col1, fill = col6)) +
geom_bar(stat = "identity") +
geom_text(aes(x = col6, y = col1, label = col1),
position = position_stack(vjust = 0.5),
size = 4)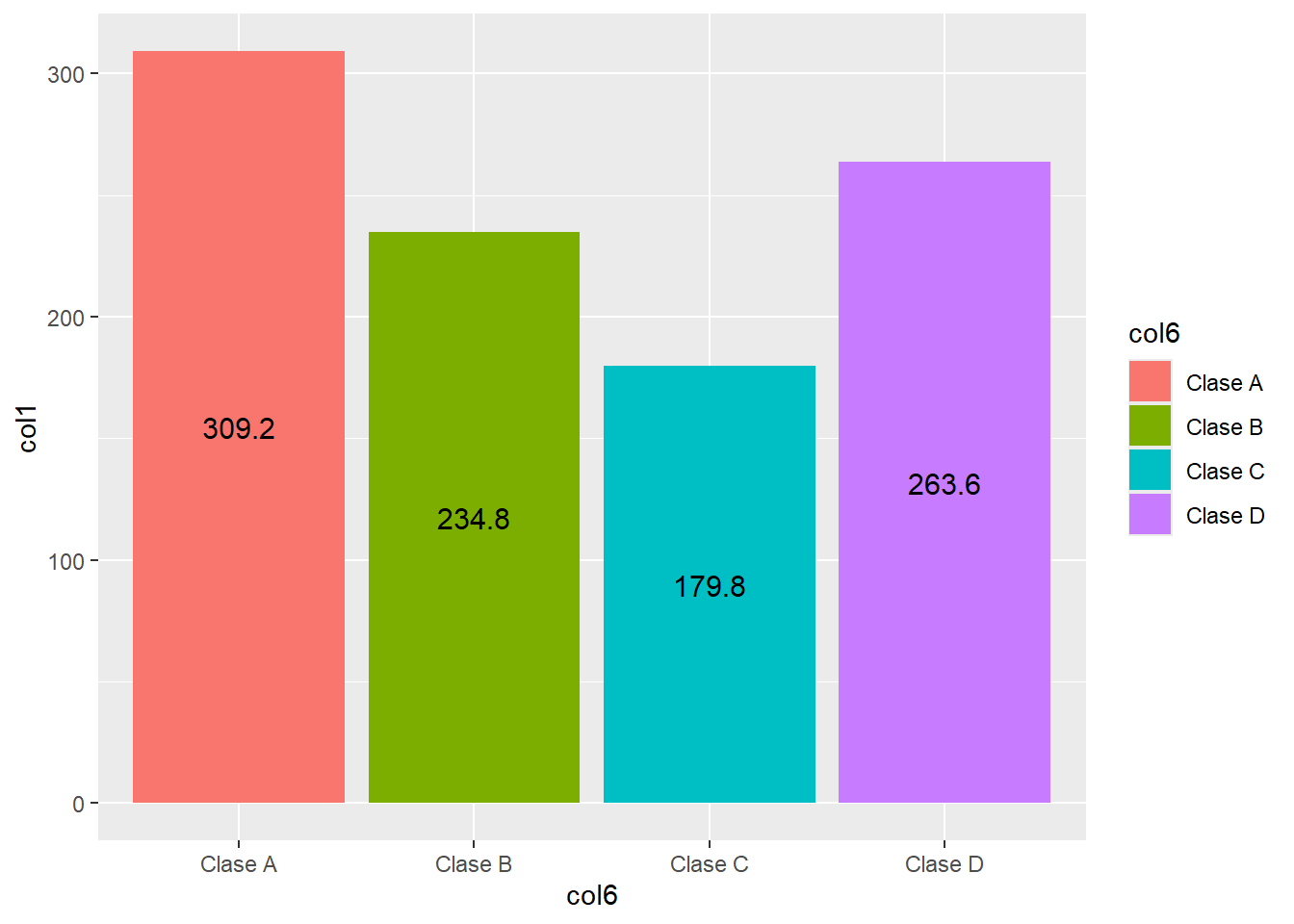
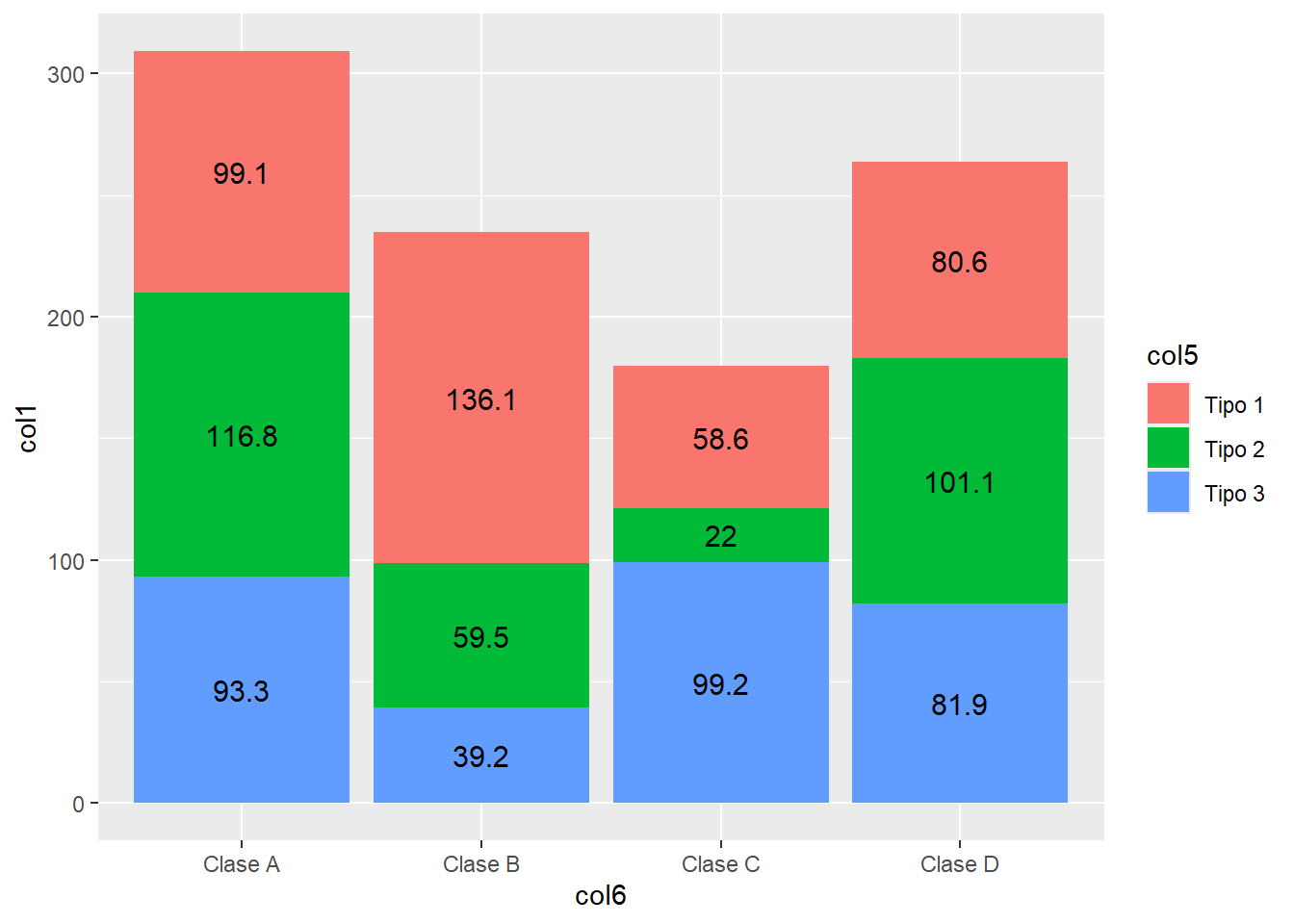
Tambien se puede realizar el conteo respecto a dos variables categóricas.
head(df[c(5, 6, 1)], n=3) col5 col6 col1
1 Tipo 3 Clase C 19.9
2 Tipo 1 Clase A 20.2
3 Tipo 2 Clase D 20.2# Extraer la variable categorica
df2 <- df[c(5, 6, 1)]
df2 <- aggregate(col1 ~ ., df2, sum)
head(df2, n=3) col5 col6 col1
1 Tipo 1 Clase A 99.1
2 Tipo 2 Clase A 116.8
3 Tipo 3 Clase A 93.3ggplot(data = df2, aes(x = col6, y = col1, fill = col5)) +
geom_bar(stat = "identity") +
geom_text(aes(x = col6, y = col1, label = col1),
position = position_stack(vjust = 0.5),
size = 4)